Declarative Data Validation with Rule-Based Approach and Functional Programming
I’ve always found client data validation to be a challenge. Self-written validators’ code easily rolls into an unreadable mess and validation libraries sometimes carry infrastructural limitations that can complicate their integration.
In this post, I want to show you a principle I use in my projects that makes validation easier and helps to write maintainable and extensible code.
To illustrate this approach, I’ve prepared a sample application, the “Mars colonizer application form”.
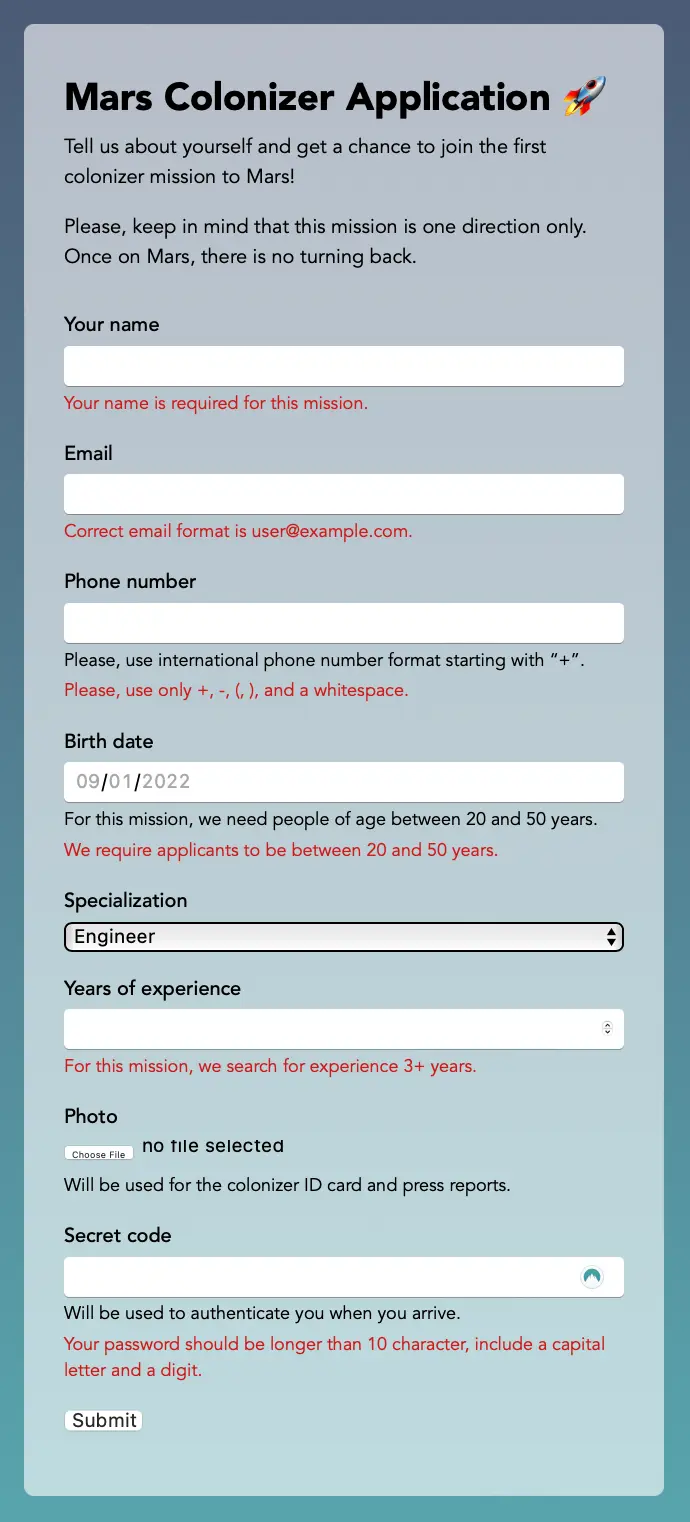
The example is pretty straightforward, but I tried to put together frequent examples of different data types (phone, mail, numeric value, date), password validation, and interdependent fields.
You can find the application and its source code by the links below:
Problem with Client Validation
The main problem with data validation on the client is that the rules by which we validate the data are too closely intertwined with the peculiarities of the user interface.
Data validation itself is often trivial, and even interdependent fields don’t make the task much more difficult. But how we show the results of validation to the user and what events should be triggered during or after validation—does.
Different projects have different validation requirements. For example, validation might be reactive—so that the form is checked as it is filled out. Sometimes, on the contrary, the form must be validated after it is completely filled out. Or the form may show additional fields after a value is entered.
When dealing with different requirements, it becomes difficult to separate the interface logic from the domain logic, but it is this separation that helps keep the complexity of the code under control.
Domain, UI, and Infrastructure Logic
By the domain logic, we will mean validation rules that are dictated by business requirements. Each of these rules has a reason to be in the real world.
For example, if the phone number or email is incorrect, we won’t be able to contact the user. This circumstance is the reason for checking the phone or email.
The UI logic is what the user sees on the screen. This most often has nothing to do with the real world. Interface logic is responsible only for interface changes. It knows nothing about the rules themselves, but it knows how to show the user an error or how to highlight an invalid field.
An example would be the appearance and disappearance of interdependent fields. In the real world, there is no reason to hide any fields. On paper forms, they don’t hide fields but explain in a text which field under which conditions to fill. But on the screen we want (and can) simplify the user’s life, so we adapt the interface by hiding and showing the right fields.
The infrastructural logic is the logic that directly runs data through the rules. We can think of it as a “validation service”, to which we feed rules and data. It checks if the data is valid. We’ll explore this logic in more detail when we get to the example, but for now, let’s talk more about the main thing—validation rules.
Power of Composition
Let’s look at the skeleton of data validation. It is based on checking the value against some criterion.
The criterion is the standard against which we check the value. In most cases, checking will boil down to comparing a primitive value to some “standard” value. Such checks are best described as pure functions that take a value as input and tell us if it is valid.
Criteria as Functions
Pure functions are functions that produce no side effects and always give the same result with the same input data. If such a function returns a Boolean value, we can call it a predicate:
const isGreaterThan5 = (value) => value > 5;Predicates are similar to validation rules: they take a value and answer whether the value is “okay” or “not okay”. Such functions are predictable, testable, and declarative—that is, they describe the result we want to get.
Pure functions are convenient to describe checks because we can specify the criterion to be checked right in the name. And since they are predicates (i.e. they always return a boolean value) - we won’t need to look at their code to understand how they work.
For example, if when validating a string we check that it contains a point and isn’t shorter than 10 characters, we can express it in code with two such functions:
const containsPointCharacter = (str) => str.includes('.');
const longerOrEqualThan10 = (str) => str.length >= 10;Each individual function checks one criterion, one “feature” of the passed value. If we want to check both criteria at the same time, we can call both functions and check that both functions returned true:
const value = 'lol.kek.cheburek';
containsPointCharacter(value) && longerOrEqualThan10(value);
// trueOr write a function that combines the functionality of these two and checks the value against both criteria:
const isValid = (value) => containsPointCharacter(value) && longerOrEqualThan10(value);This way we can assemble more complex rules from simpler ones—compose them.
Composition of Rules
In a general sense, the composition is making complex things from simpler things. Here we compose big (complex) checking rules from small (simple) ones.
The simpler and more intuitive the mechanism for making complex rules, the fewer mistakes we will make when describing them. We can reduce any complex rule to a set of simple ones using binary logic. For example, we can use the operation AND && to check all criteria at once and OR || to check at least one.
Duplication and Reusable Code
Since each function checks one criterion, one “feature”, they are abstract enough to be part of several rules at once.
For example, we can use the isString function in both phone and mail checks:
const isString = (x) => typeof x === 'string';If we find the same criteria in the validation rules, we can reuse functions already written to reduce duplication.
Next, we’ll see in examples that the fight against duplication doesn’t end there. We will look at how you can bring template actions into “sup-programs”. All according to SICP 😃
Application Example
Let’s move on from theory to practice and write a sample application from scratch. We’ll create the validation for the Mars colonizer application form.
I won’t show the code for the markup, the styles, and most of the DOM handling because it’s not that important for this topic. But you can always see the source code on GitHub or look it up in the sample application.
This example is intentionally simple. In real projects, validation will be more complicated and relations between rules may be more intricate. But it’s much easier to demonstrate new concepts using simple examples. So let’s get to work.
Defining the Rules
Let’s start with the “core” of the check—the rules. Assume that we have already figured out all the business requirements and written them down. Let’s say the requirements are:
- Phone and email must be in the correct format;
- The phone must start with a “+”, i.e. it must be international;
- The user must be at least 20 years old and not older than 50;
- The user should choose the specialty from the list offered;
- If their specialty is not in the list, the user should specify it in the field below, the string length, in this case, should not exceed 50 characters;
- The work experience must be 3+ years;
- The passcode shouldn’t be shorter than 10 characters, have at least one uppercase letter and at least one digit.
All of these rules are part of the domain because there is a reason for each of them to exist in the real world. Phone and email are needed to contact the user. Age is between 20 and 50—so that colonizers can better survive on board and the new planet. The specialties listed have higher priority because colonizers need biologists, engineers, and psychologists the most, etc.
Each of these rules we already can turn into a predicate, but first I suggest looking at the data we are working with and modeling it.
Modeling a Form Type
I will be using TypeScript in the code examples. Most of the examples will be almost identical to JavaScript code, but if you still feel unsure, I recommend reading TypeScript Handbook.
So, we will represent the data from the form as the ApplicationForm type. Each field of this type will be a field in the form itself. We will represent field types as wrapper types to avoid obsession with primitives.
// types.ts
export type ApplicationForm = {
name: ApplicantName;
phone: PhoneNumber;
email: EmailAddress;
birthDate: BirthDate;
photo: UserPhoto;
specialty: KnownSpecialty;
customSpecialty: UnknownSpecialty;
experience: ExperienceYears;
password: Password;
};Let’s design the wrapper types for the fields:
// types.ts
type ApplicantName = string;
type PhoneNumber = string;
type EmailAddress = string;
type BirthDate = DateString;
type UserPhoto = Image;
type KnownSpecialty = 'engineer' | 'scientist' | 'psychologist';
type UnknownSpecialty = string;
type ExperienceYears = NumberLike;
type Password = string;The types NumberLike, DateString, and Image are abstract enough to put them in a separate module. Create globally accessible annotations in shared-kernel.d.ts and add these types there. Besides them, let’s add some auxiliary types that we will need in the future:
// shared-kernel.d.ts
// Optional value helpers:
type Nullable<T> = T | null;
type Optional<T> = T | undefined;
// Array wrapper:
type List<T> = T[];
// Since HTML inputs return strings
// we're going to need to have a type
// that reflects our intent to get a number:
type NumberLike = string;
type Comparable = string | number;
// Improving the readability of the code
// and adding details about the domain:
type DateString = string;
type TimeStamp = number;
type NumberYears = number;
type LocalFile = File;
type Image = LocalFile;We describe the form as ApplicationForm. We will use this type in the form validation rules as a signature for the input data.
Implementing the Validation Criteria
We will implement the rules as predicate functions. The functions will be pure and depend only on input data. It means that they will know nothing about the UI.
All rules will take a form object as input and return a boolean value. That is, they will provide the same “public API” which we can represent as a signature:
ApplicationForm => booleanAll other application logic will depend on these rules, not the other way around. This way we isolate the rules’ logic and decouple it from the rest of the code.
Let’s start with the name. By requirement, it just has to exist. There are no additional restrictions, so we’ll check the value for truth:
// validation.ts
export const validateName = ({ name }) => !!name;Note that the function is quite concrete—it takes a form object as input, from which it gets the name. However, checking for truthiness is a fairly common operation. We can put such a check into a separate function to reuse it in the future:
// utils.ts
export const exists = <TEntity>(x: TEntity) => !!x;
// validation.ts
export const validateName = ({ name }) => exists(name);This is how we separate levels of abstraction. We keep the repeating operation in the exists function, and use it in the specific case of name validation.
Abstraction allows us to “remove unnecessary details”. When checking a name, we don’t care how we check for its existence. We “sweep” the check details into a separate function and rely on it as a whole—as a single action. This makes the code reusable and readable.

Let’s move on to the email. Suppose our email validation rule consists of two criteria: “the string must contain @” and “the string must contain a period”. We can concatenate such criteria with an AND:
// validation.ts
export const validateEmail = ({ email }) => email.includes('@') && email.includes('.');With the phone number, it’s more interesting. There are two criteria there, too: “international format” and “allowed characters only”. We can write it like this:
// validation.ts
const validatePhone = ({ phone }) => phone.startsWith('+') && phone.search(/[^ds-()+]/g) < 0;…But such code smells a bit, because it is hard to understand why there is a “+” here and why we are looking for this particular pattern. Instead, we can break the “features” into functions, and their names declare the intention:
// validation.ts
const onlyInternational = ({ phone }) => phone.startsWith('+');
const onlySafeCharacters = ({ phone }) => phone.search(/[^ds-()+]/g) < 0;Now you may notice that the onlySafeCharacters function has one more operation that will come in handy in the future—search by string. Let’s put this operation into a function and name it clearly, too:
// utils.ts
export const contains = (value: string, pattern: RegExp) => value.search(pattern) >= 0;
// validation.ts
const onlySafeCharacters = ({ phone }) => !contains(phone, /[^ds-()+]/g);To check the date of birth we use the criteria “date as a string with a valid format” and “user’s age between 20 and 50”.
// utils.ts
export const inRange = (value: Comparable, min: Comparable, max: Comparable) =>
value >= min && value <= max;
export const yearsOf = (date: TimeStamp): NumberYears =>
new Date().getFullYear() - new Date(date).getFullYear();
// validation.ts
const MIN_AGE = 20;
const MAX_AGE = 50;
const validDate = ({ birthDate }) => !Number.isNaN(Date.parse(birthDate));
const allowedAge = ({ birthDate }) => inRange(yearsOf(Date.parse(birthDate)), MIN_AGE, MAX_AGE);Specialty check refers to different interdependent fields: if the user has selected a specialty from the list, use it, and if not—use an additional field and check that the length of its value is not more than 50 characters.
// validation.ts
const MAX_SPECIALTY_LENGTH = 50;
const DEFAULT_SPECIALTIES: List<KnownSpecialty> = ['engineer', 'scientist', 'psychologist'];
const isKnownSpecialty = ({ specialty }) => DEFAULT_SPECIALTIES.includes(specialty);
const isValidCustom = ({ customSpecialty: custom }) =>
exists(custom) && custom.length <= MAX_SPECIALTY_LENGTH;Notice that we have no problem with interdependent fields. Functions have enough data and context to check such fields, because we’re giving the entire form object as input, not field values individually.
We can think of this object as a unit of information transfer. We sort of pack into it everything we might need to check the form. For interdependent fields, such an object turns out to be self-sufficient. The main thing is to make sure that the data inside relates to the same task, and that the level of abstraction is the same for all fields.
Next, experience validation. The rules require colonists to have at least 3 years of experience in their field. Let’s write it that way, but don’t forget that inputs return strings, and convert the value to a number:
const isNumberLike = ({ experience }) => Number.isFinite(Number(experience));
const isExperienced = ({ experience }) => Number(experience) >= MIN_EXPERIENCE_YEARS;Finally, we check the password. It must be at least 10 characters long, contain at least one uppercase letter and at least one number:
const atLeastOneCapital = /[A-Z]/g;
const atLeastOneDigit = /d/gi;
const hasRequiredSize = ({ password }) => password.length >= MIN_PASSWORD_SIZE;
const hasCapital = ({ password }) => contains(password, atLeastOneCapital);
const hasDigit = ({ password }) => contains(password, atLeastOneDigit);Notice how the combination of the contains function and specific regular expressions makes the code look like a sentence. When we properly divide the levels of abstraction and don’t mix them up, the details of the implementation don’t get in the way of understanding the intention.
That’s why we separate the more abstract operations into separate functions and give them clear names—this is how we make the intentions clearer.
Composing Validation Rules
At this point, we’ve prepared the data validation criteria. Now we can build rules from them to validate the entire form.
In some cases, the criterion is itself a rule, as in the case of name or email. We can use such functions without any additional operations. In other cases, we need to combine the criteria into more complex rules, like a password, for example.
const validatePassword = (form: ApplicationForm) =>
hasRequiredSize(form) && hasCapital(form) && hasDigit(form);It is easy to see that a similar arrangement will be repeated in other cases:
const validateBirthDate = (form: ApplicationForm) => validDate(form) && allowedAge(form);
const validateExperience = (form: ApplicationForm) => isNumber(form) && isExperienced(form);
// …But we can put this operation—combining different criteria—into a function! Then we won’t have to call the criterion functions by hand and pass them arguments. We can automate this and make the intention more explicit. Let’s write functions that compose the criteria into rules:
// services/validation.ts
export function all(rules) {
return (data) => rules.every((isValid) => isValid(data));
}
export function some(rules) {
return (data) => rules.some((isValid) => isValid(data));
}Note that these composer functions don’t care what rules they take as input. The point of composers is to take a list of rules and run some value through them. We have successfully extracted a repeating set of actions, that is, we have again separated levels of abstraction.
To prove that such composers can work with any rules, let’s add type signatures—we will see that these functions can be made generic:
// services/validation.ts
export type ValidationRule<T> = (data: T) => boolean;
type RequiresAll<T> = ValidationRule<T>;
type RequiresAny<T> = ValidationRule<T>;
export function all<T>(rules: List<ValidationRule<T>>): RequiresAll<T> {
return (data) => rules.every((isValid) => isValid(data));
}
export function some<T>(rules: List<ValidationRule<T>>): RequiresAny<T> {
return (data) => rules.some((isValid) => isValid(data));
}And now we can use composers to assemble the validation criteria into rules:
//validation.ts
const phoneRules = [onlyInternational, onlySafeCharacters];
const birthDateRules = [validDate, allowedAge];
const specialtyRules = [isKnownSpecialty, isValidCustom];
const experienceRules = [isNumberLike, isExperienced];
const passwordRules = [hasRequiredSize, hasCapital, hasDigit];
export const validatePhone = all(phoneRules);
export const validateBirthDate = all(birthDateRules);
export const validateSpecialty = some(specialtyRules);
export const validateExperience = all(experienceRules);
export const validatePassword = all(passwordRules);We can already use these rules, for example, if we want to validate a specific field. But we can go further and build a validator for the whole form, using the same linkers!
Building the Whole Form Validator
Rules have the same signature as criteria, so we can use all and some to compose rules into even more complex rules. For example, to validate the form from the example we can write:
// validation.ts
export const validateForm = all([
validateName,
validateEmail,
validatePhone,
validateBirthDate,
validateSpecialty,
validateExperience,
validatePassword
]);…And the validateForm function will check that each rule (no longer a criterion, but a whole rule) is satisfied.
Validation Errors
The function validateForm tells us if the form is valid or not. But it cannot tell you which particular field has errors and which rule has failed. Filling out a form like this would be a nightmare for the user, so let’s fix that.
Designing Validation Result
First of all, let’s think about in what form we want to get the result. I thought an object with two fields would be sufficient: valid and errors. The first will answer the question if the form is valid and the second will contain error messages for each invalid field.
// services/validation.ts
export type ErrorMessage = string;
export type ErrorMessages<TData> = Partial<Record<keyof TData, ErrorMessage>>;
export type ValidationRules<TData> = Partial<Record<keyof TData, ValidationRule<TData>>>;
type ValidationResult<TData> = {
valid: boolean;
errors: ErrorMessages<TData>;
};Errors and rules will then be displayed as objects, with the keys being form fields and the values being error messages and rule functions, respectively:
// validation.ts
type ApplicationRules = ValidationRules<ApplicationForm>;
type ApplicationErrors = ErrorMessages<ApplicationForm>;
const rules: ApplicationRules = {
name: validateName,
email: validateEmail,
phone: validatePhone,
birthDate: validateBirthDate,
specialty: validateSpecialty,
experience: validateExperience,
password: validatePassword
};
const errors: ApplicationErrors = {
name: 'Your name is required for this mission.',
email: 'Correct email format is user@example.com.',
phone: 'Please, use only “+”, “-”, “(”, “)”, and a whitespace.',
birthDate: 'We require applicants to be between 20 and 50 years.',
specialty: 'Please, use up to 50 characters to describe your specialty.',
experience: 'For this mission, we search for experience 3+ years.',
password: 'Your password must be longer than 10 characters, include a capital letter and a digit.'
};Again, the objects of errors and rules can be any objects, so we can describe them as generics. The validator itself won’t care about this either—its task will be to run each field through the corresponding rule and write the result. That’s why we won’t create a single validator, but rather a factory.
Creating Validator Factory
A factory is an entity that creates other entities. In our case, it’s a function that will create functions. We will again put the same type of actions into a “superprogram”, the createValidator function:
// services/validation.ts
export function createValidator<TData>(
rules: ValidationRules<TData>,
errors: ErrorMessages<TData>
) {
return function validate(data: TData): ValidationResult<TData> {
const result: ValidationResult<TData> = {
valid: true,
errors: {}
};
Object.keys(rules).forEach((key) => {
// Find a validation rule for each field:
const field = key as keyof TData;
const validate = rules[field];
// If no rule skip this field:
if (!validate) return;
// If the value is invalid show an error:
if (!validate(data)) {
result.valid = false;
result.errors[field] = errors[field];
}
});
return result;
};
}This function takes rules and errors as input and returns a validator function. This validator will take data, check each field with a matching rule, and record an error if the value fails.
We can use such a factory like this:
// validation.ts
export const validateForm = createValidator(rules, errors);
// The validateForm signature will be: ApplicationForm => ValidationResult<ApplicationForm>.
// Thanks to the generics, the function understands which data structure it is going to work with.The validator itself we can use like this:
// main.ts
// …
const data: ApplicationForm = Object.fromEntries(new FormData(e.target));
const { valid, errors } = validateForm(data);
// If !valid show errors to the user.
// …Note that we keep createValidator (as well as all and some) separate from the rules themselves. These functions handle the “infrastructural” task of linking the rules and presenting the result.
This is how we separate the domain and infrastructure logic. Now, if we need to change the structure of the validation result, we don’t need to change the rules. We will only need to change the infrastructure, “service” code.
Patterns, Pattern-matching, and Metaprogramming
Some may have seen this approach as a distorted “Strategy” pattern and some as “not-very-good-and-not-well-defined-pattern-matching”. On the whole, you’re right.
The rule-oriented declarative approach can be thought of as an abstraction management tool. It’s like we’re writing programs that can generate a large number of other, more specific, but working by almost identical rules.
The advantage is that with less effort we can generate a lot of “almost identical” code without duplication. And while we are on the subject of advantages, let’s evaluate the rule-based approach to validation in general.
Advantages of Rule-Based Approach
I counted five of them.
Extensibility
Adding new rules or changing existing rules becomes easier. At the very least, it’s always clear where to look for the place to update. For example, if we need to add a new criterion for a password, say, to contain a wildcard, then we add a new feature:
const hasSpecialCharacter = ({ password }) => contains(password, specialCharactersRegex);…And then add it to the list of rules for password verification:
const passwordRules = [hasRequiredSize, hasCapital, hasDigit, hasSpecialCharacter];If we need to update a function, say, replace the mail check with a regular expression check, we will only update the validateEmail function:
const validateEmail = ({ email }) => emailRegex.test(email);If we need to add a new field to the form, then we update the list of rules and errors. Suppose we want to add a field with the size of the clothes, in order to sew the form correctly:
const validateSize = ({size}) => // ...The validation rule.
const rules = {
// ...All the other rules.
size: validateSize,
}
const errors = {
// ...All the other error messages.
size: 'Please, use American size chart.'
}And if you want to remove the field from the form, you just need to find and delete the code associated with it.
Readability
The declarative style is easier to read than the imperative style. When writing declaratively it is easier to spot different levels of abstraction and explain your intent in terms of the subject area. This allows you to avoid wasting resources on “parsing” unnecessary details in your head later when reading the code.
Testability
Pure functions are easier to test. You don’t need to “mock services” and “configure the infrastructure“ for them, a test-runner and test data are enough. Each rule can be tested in isolation, or if there are many of them, you can run the tests in parallel.
The validation service itself can be checked once. If we made sure that it composes the functions correctly and runs the value through all the rules, we won’t need to check it every time.
Live Documentation
Rules described by functions with clear names can be given to “non-programmers” to check. (Not always, of course, but ideally, you can.) Such rules can be made part of the ubiquitous language from Domain Driven Design.
No Dependencies
You don’t need any third-party libraries for this kind of validation. This may not work for some people for various reasons—this is more of an advantage for me specifically.
I generally try to choose dependencies carefully. If some piece of functionality I can write myself, and it won’t be a buggy bike and a black hole in terms of resources and time, then I’ll consider the “write it myself” option.
If you really need the library, then the pure functions won’t be difficult to pair with it. Especially if the library also supports the declarative approach, like React Hook Form.
In general, any approach that’s based on lightweight function-type abstractions is relatively cheap to combine with libraries and third-party services. Rule-based validation is just one such approach.
Disadvantages
We cannot do without disadvantages here. Here’s what I have encountered while using such validators.
Need Contract for Error Handling
It’s not always clear what we should return as a result of validation. In the example, we return error messages for each rule, but maybe we need to report errors for each criterion or the first character where the error occurred, or something else. This requirement may change from project to project.
You could put the contract definition in a separate function or write a more general validator, but then the code could become too complex.
It helps me to keep the infrastructure logic—factories, composers, runners—separate from the rules. In that case, replacing or extending the error contract is easier.
Need to Determine “Atomicity” of Rules
It is not always clear how primitive the rules should be. There is, for example, such validator, where the rules are also declarative, but work mostly with primitive criteria. For forms such rules will probably work fine, but for serialized DTOs validation during deserialization they might not.
It’s hard to make recommendations here because the approach will depend on the specific project. In my code, I try to avoid obsession with primitives and use types from the domain. Different teams may have different opinions on this, maybe your project won’t fit this way.
Performance and Converters
There are two rules in the example code that smell a bit: validateBirthDate and validateExperience. Their criterion functions convert strings to dates and numbers and do so every time they are called.
// Date.parse called _twice_ when just _one_ field is checked:
const validDate = ({ birthDate }) => !Number.isNaN(Date.parse(birthDate));
const allowedAge = ({ birthDate }) => inRange(yearsOf(Date.parse(birthDate)), MIN_AGE, MAX_AGE);Complex structures can lead to performance degradation. Ideally, conversion should be done once. (And it would be nice to cover the structure with types before and after conversion.) We could use the type function:
type BirthDate = TimeStamp;
type ExperienceYears = YearsNumber;
type ApplicantForm = {
// ...
birthDate: BirthDate;
experience: ExperienceYears;
};
function toApplicantForm(raw: RawApplicantForm): ApplicantForm {
return {
...raw,
birthDate: Date.parse(raw.birthDate),
experience: Number(experience)
};
}Validator as Unwanted Dependency
If you get distracted, you can accidentally drag the validation service as a dependency into all the other modules.
I try to make sure the domain logic is clean and not dependent on third-party services. It usually helps to split the value check and its retrieval from the object. In the example of mail validation it would be like this:
// Domain function, works with a domain primitive:
const isValidEmail = (email: EmailAddress) => email.includes('@') && email.includes('.');
// Function in the application layer, works with the whole form object:
const validateEmail = ({ email }: ApplicationForm) => isValidEmail(email);Then the business rules would be even cleaner and more independent, but most often it’s an overhead. Sometimes you can sacrifice “cleanliness” for brevity. However, the cleaner the functions are the easier the DTO validation is when deserializing them.
Also, you’ll still need to think about error handling. But we’ll talk about it some other time 😃
Sources
As usual, I’ve put together a huge list of sources and references for the text of this post. Enjoy!
Application and Source Code
Common Computer Science Terms
Declarative Approach and Functional Programming
- Pure Functions
- Function Composition
- Predicate Functions
- Higher-Order Functions.
- Pattern-Matching
- Declarative Programming
Software Design and Architecture
- Domain-Driven Design
- Data Transfer Object
- Shared kernel
- Strategy Patter
- “Domain Modeling Made Functional”, Scott Wlaschin
- Clean Architecture on Frontend
- DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together
- Generics in TypeScript
- TypeScript Handbook
Abstraction and Levels of Complexity
- Abstraction Layer
- Separation of Concerns
- Climbing the infinite ladder of abstraction
- Primitive Obsession
Books About This Topic
- Structure and Interpretation of Computer Programs by H. Abelson, G. J. Sussman, J. Sussman
- Domain Modeling Made Functional by Scott Wlaschin